Model Predictions
Data → Predictions!
April 30, 2024
Written by BittermanLab
Looking at Logits
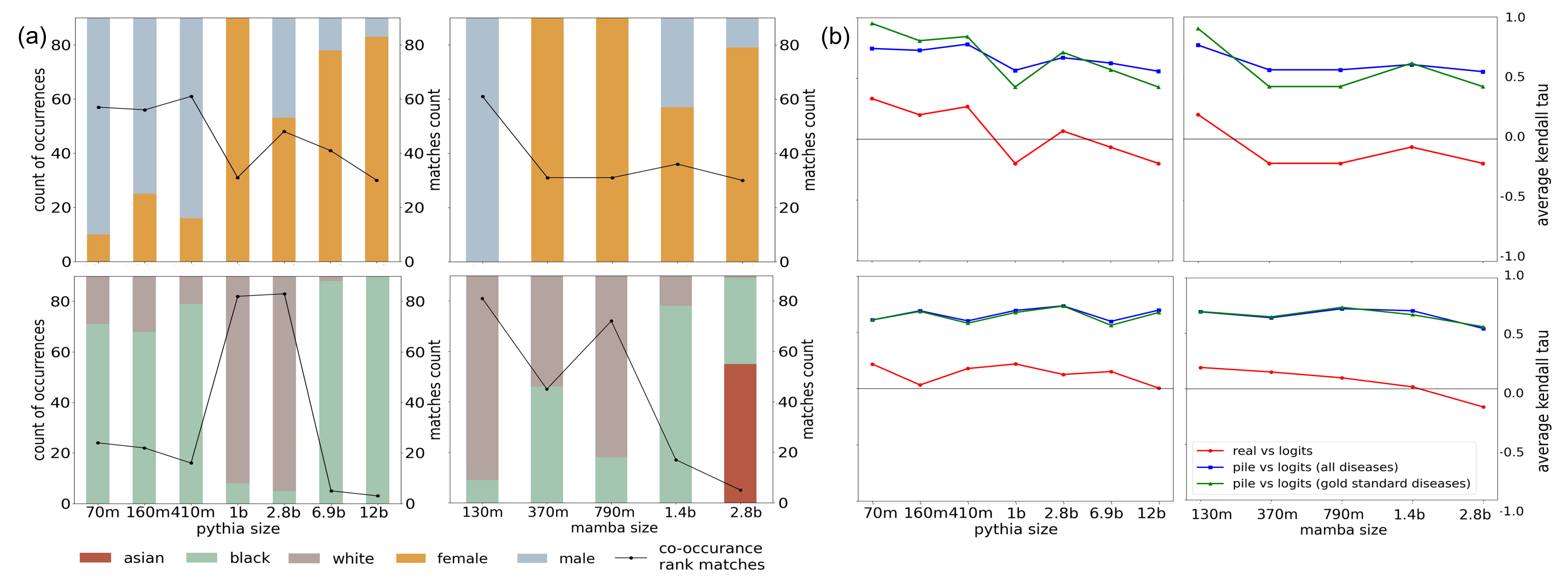
Here, we look at how different models (Pythia/Mamba) rank diseases based on demographic factors like gender and race.
Logits Rank vs Co-occurrence
We compared two methods: one based on the model's internal calculations (logits), and the other based on how often diseases and demographics appear together in a large dataset called ThePile.
The stacked bar chart below (a) visually represents the frequency with which certain genders and races are associated with different diseases. Each bar in the chart is segmented to show the proportion of each demographic group’s association with various diseases. The black line overlaying the bars indicates the frequency at which the model’s top-ranked demographic aligns with the demographic most frequently associated with each disease in ThePile dataset.
Our analysis revealed a notable trend: as the models increased in size and complexity, their accuracy in mirroring the real-world distribution of demographics diminished. This means that larger models were less effective at accurately reflecting the actual prevalence of diseases across different demographic groups, highlighting a potential limitation in the models’ ability to generalize from the training data to real-world scenarios. This finding underscores the need for careful consideration of model size and complexity in the development and application of predictive models in healthcare.
Logits Rank vs Co-occurrence vs Real Prevalence
In this section, we compared the model’s rankings with real-world prevalence data (b). Surprisingly, the model’s rankings did not align with the actual occurrence of diseases in different demographic groups. This indicates that the models may not accurately reflect real-world medical knowledge.
However, we found that the models tended to align more closely with ThePile’s co-occurrence data than with real-world prevalence. This suggests that while the models were not particularly good at predicting real-world disease prevalence, they were somewhat better at reflecting the frequency of diseases and demographics in large datasets.
Rank vs Co-occurrence Counts
Finally, we looked at how the frequency of diseases mentioned in ThePile affected the model's performance. We found that the models performed similarly across different quartiles of disease co-occurrence counts. This suggests that the model's accuracy didn't improve based on how often diseases were mentioned in the dataset.
For more detailed insights and to access our full dataset, please visit our project page at Cross-Care Downloads.
Continue reading about Logits and Co-Occurrences